Reads to reference genome & gene predictions
Introduction
Cheap sequencing has created the opportunity to perform molecular-genetic analyses on just about anything. Conceptually, doing this would be similar to working with traditional genetic model organisms. But a large difference exists: For traditional genetic model organisms, large teams and communities of expert assemblers, predictors, and curators have put years of efforts into the prerequisites for most genomic analyses, including a reference genome and a set of gene predictions. In contrast, those of us working on “emerging” model organisms often have limited or no pre-existing resources and are part of much smaller teams.
The steps below are meant to provide some ideas that can help obtain a reference genome and a reference geneset of sufficient quality for ecological and evolutionary analyses. They are based on (but updated from) work we did for the fire ant genome.
Specifically, focusing on low coverage of ~0.5% of the fire ant genome, we will:
- inspect and clean short (Illumina) reads,
- perform genome assembly,
- assess the quality of the genome assembly using simple statistics,
- predict protein-coding genes,
- assess quality of gene predictions,
- assess quality of the entire process using a biologically meaningful measure.
Please note that these are toy/sandbox examples simplified to run on laptops and to fit into the short format of this course. For real projects, much more sophisticated approaches are needed!
Test that the necessary software are available
Run seqtk. If this prints “command not found”, ask for help, otherwise, move to the next section.
Set up directory hierarchy to work in
Start by creating a directory to work in. Drawing on ideas from Noble (2009) and others, we recommend following a specific convention for all your projects.
For the purpose of these practicals we will use a slightly simplified version of the directory structure explained above.
For each practical (analysis) that we will perform, you should:
- have a main directory in your home directory (e.g., 2019-09-xx-read_cleaning)
- have input data in a relevant subdirectory (input)
- work in a relevant subdirectory (tmp)
- copy final results to a relevant subdirectory (results)
Each directory in which you have done something should include a WHATIDID.txt file in which you log your commands.
Being disciplined about this is extremely important. It is similar to having a laboratory notebook. It will prevent you from becoming overwhelmed by having too many files, or not remembering what you did where.
Sequencing an appropriate sample
Less diversity and complexity in a sample makes life easier: assembly algorithms really struggle when given similar sequences. So less heterozygosity and fewer repeats are easier. Thus:
- A haploid is easier than a diploid (those of us working on haplo-diploid Hymenoptera have it easy because male ants are haploid).
- It goes without saying that a diploid is easier than a tetraploid!
- An inbred line or strain is easier than a wild-type.
- A more compact genome (with less repetitive DNA) is easier than one full of repeats - sorry, grasshopper & Fritillaria researchers!
Many considerations go into the appropriate experimental design and sequencing strategy. We will not formally cover those here & instead jump right into our data.
Part 1: Short read cleaning
Sequencers aren’t perfect. All kinds of things can and do go wrong. “Crap in – crap out” means it’s probably worth spending some time cleaning the raw data before performing real analysis.
Initial inspection
FastQC (documentation) can help you understand sequence quality and composition, and thus can inform read cleaning strategy.
Symlink the raw sequence files (‘/import/teaching/bio/data/reads.pe*.fastq.gz) to a relevant input directory (e.g., ~/2019-09-xx-read_cleaning/input/).
Run FastQC on the reads.pe2 file. The command is given below but you will need to replace REPLACE with the path to a directory (this could be your tmp directory) before running the command. The --nogroup option ensures that bases are not grouped together in many of the plots generated by FastQC. This makes it easier to interpret the output in many cases. The --outdir option is there to help you clearly separate input and output files. To learn more about these options run fastqc --help in the terminal.
fastqc --nogroup --outdir REPLACE input/reads.pe2.fastq.gz
Remember to log the commands you used in the WHATIDID.txt file.
Your resulting directory structure (~/2019-09-xx-read_cleaning), should look like this:
2019-09-xx-read_cleaning
├── input
│ ├── reads.pe1.fastq.gz -> /import/teaching/bio/data/reads.pe1.fastq.gz
│ └── reads.pe2.fastq.gz -> /import/teaching/bio/data/reads.pe2.fastq.gz
├── tmp
│ ├── reads.pe2_fastqc.html
│ └── reads.pe2_fastqc.zip
├── results
└── WHATIDID.txt
What does the FastQC report tell you? (the documentation clarifies what each plot means). For comparison, have a look at some plots from other sequencing libraries: e.g, [1], [2], [3].
![[1]](/genomicscourse/2019/practicals/reference_genome/img-qc/per_base_quality.png){kind=link}
![[2]](/genomicscourse/2019/practicals/reference_genome/img-qc/qc_factq_tile_sequence_quality.png){kind=link}
![[3]](/genomicscourse/2019/practicals/reference_genome/img-qc/per_base_sequence_content.png){kind=link}
Decide whether and how much to trim from the beginning and end of our sequences. What else might you want to do?
Below, we will perform three cleaning steps:
- Trimming the ends of sequence reads using seqtk.
- K-mer filtering using kmc3.
- Removing sequences that are of low quality or too short using seqtk.
Other tools including fastx_toolkit, kmc2 and Trimmomatic can also be useful.
Trimming
seqtk (documentation) is a fast and lightweight tool for processing FASTA and FASTQ sequences.
Based on the results from FastQC, replace REPLACE and REPLACE below to appropriately trim from the beginning (-b) and end (-e) of the sequences. Do not trim too much!! (i.e. not more than a few nucleotides). Algorithms are generally able to cope with a small amount of errors. If you trim too much of your sequence, you are also eliminating important information.
seqtk trimfq -b REPLACE -e REPLACE input/reads.pe2.fastq.gz > tmp/reads.pe2.trimmed.fq
This will only take a few seconds (make sure you replaced REPLACE).
Let’s similarly inspect the paired set of reads, reads.pe1, and appropriately trim them.
seqtk trimfq -b REPLACE -e REPLACE input/reads.pe1.fastq.gz > tmp/reads.pe1.trimmed.fq
K-mer filtering, removal of low quality and short sequences
Say you have sequenced your sample at 45x genome coverage. The real coverage distribution will be influenced by factors including DNA quality, library preparation type and local GC content, but you might expect most of the genome to be covered between 20 and 70x. In practice, the distribution can be very strange. One way of rapidly examining the coverage distribution before you have a reference genome is to chop your raw sequence reads into short “k-mers” of 31 nucleotides, and count how often you get each possible k-mer. An example plot of k-mer frequencies from a haploid sample sequenced at ~45x coverage is shown below:
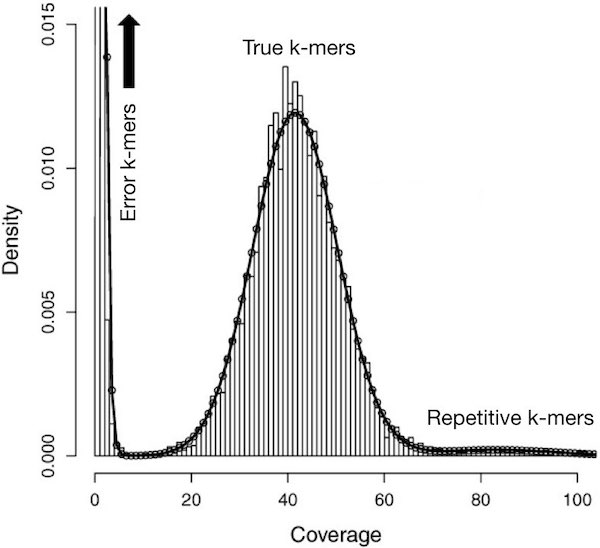
Surprisingly, many sequences are extremely rare (e.g., present only once). These are likely to be errors that appeared during library preparation or sequencing, or could be rare somatic mutations. Although not show in the above graph, other sequences may exist at 10,000x coverage. These could be pathogens or repetitive elements. Both extremely rare and extremely frequent sequences can confuse assembly software and eliminating them can reduce subsequent memory, disk space and CPU requirements considerably.
Below, we use kmc3 to trim extremely rare k-mers from the reads. Multiple alternative approaches (e.g., using khmer) exist. Trimming rare k-mers can cause some reads to become too short to be informative. We remove such reads in the subsequent step using seqtk. In the same same step, we also ask seqtk to remove reads containing low quality. Finally, because we have discarded certain reads (either because they had become too short or because they contained low quality bases) some reads may have become “orphaned”, i.e., they are no longer paired. We eliminate these in the next step because subsequent analysis (e.g., genome assembly, or variant calling) often assume all reads to be paired. Understanding the exact commands – which are a bit convoluted – is unnecessary. It is important to understand the concept of k-mer filtering and the reasoning behind each step.
# 1. Build a database of k-mers (includes count for each unique k-mer)
# 1.1 Make a list of files to make k-mer database from
ls tmp/reads.pe1.trimmed.fq tmp/reads.pe2.trimmed.fq > tmp/file_list_for_kmc
# 1.2 Count k-mers. This will produce two files in your tmp/ directory:
# 21-mers.kmc_pre and 21-mers.kmc_suf. The last argument (tmp) tells
# kmc where to put intermediate files during computation; these are
# automatically deleted afterwards.
kmc -k21 @tmp/file_list_for_kmc tmp/21-mers tmp
# 2. Trim reads so that k-mers observed less than 3 times are eliminated.
kmc_tools -t1 filter -t tmp/21-mers tmp/reads.pe1.trimmed.fq -ci3 tmp/reads.pe1.trimmed.norare.fq
kmc_tools -t1 filter -t tmp/21-mers tmp/reads.pe2.trimmed.fq -ci3 tmp/reads.pe2.trimmed.norare.fq
# 3. Remove reads shorter than 50 bp and those containing low quality bases.
seqtk seq -L 50 -q 10 tmp/reads.pe1.trimmed.norare.fq > tmp/reads.pe1.trimmed.norare.noshort.highqual.fq
seqtk seq -L 50 -q 10 tmp/reads.pe2.trimmed.norare.fq > tmp/reads.pe2.trimmed.norare.noshort.highqual.fq
# 4. Remove orphaned reads
# 4.1 Collect read ids that appear in both files
cat tmp/reads.pe1.trimmed.norare.noshort.highqual.fq tmp/reads.pe2.trimmed.norare.noshort.highqual.fq | seqtk comp | cut -f1 | sort | uniq -d > tmp/paired_read_ids
# 4.2 Extract reads corresponding to the selected ids from both the files
seqtk subseq tmp/reads.pe1.trimmed.norare.noshort.highqual.fq tmp/paired_read_ids > tmp/reads.pe1.clean.fq
seqtk subseq tmp/reads.pe2.trimmed.norare.noshort.highqual.fq tmp/paired_read_ids > tmp/reads.pe2.clean.fq
# 5. Copy over the cleaned reads to a results directory
cp tmp/reads.pe1.clean.fq tmp/reads.pe2.clean.fq results
Inspecting quality of cleaned reads
Which percentage of reads have we removed overall? (hint: wc -l can count lines in a non-gzipped file). Is there a general rule about how much we should be removing?
Run fastqc again, this time on reads.pe2.clean.fq. Which statistics have changed? Does the “per tile” sequence quality indicate to you that we should perhaps do more cleaning?